
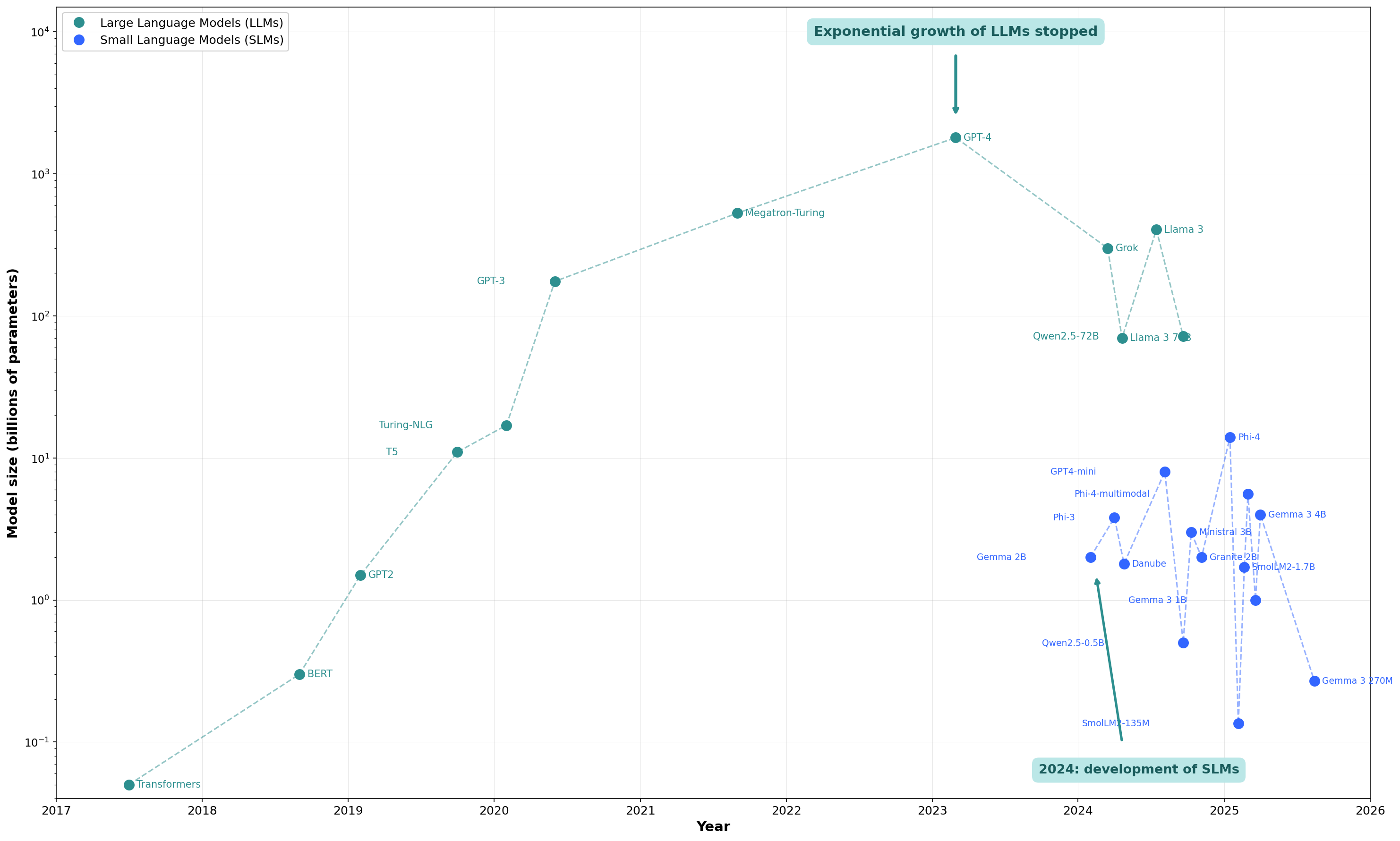
Why do we need Small Language Models?
From Language Models to Reasoning Machines

AI companies are focused on larger models and expensive hardware to achieve AGI. However, small models can handle most user queries and achieve performance that approximates that of larger models. Context windows are growing 3-5x every year, reducing the need for models to store knowledge and allowing them to get even smaller. Larger context windows will narrow the gap and make the knowledge stored in large models less desirable and an unwanted risk of hallucination. Small models of pure reasoning and nearly zero knowledge can run on a local device, requiring less frequent retraining. They could even be printed into hardware for low consumption, high speed, where they could run many reasoning steps. While frontier models could reach AGI by building larger black boxes, pure-reasoning models can reveal the mathematics of AI. Frontier models demand massive data centers, fiber optics, superconductors, and even nuclear-level power, while the human brain runs superior reasoning on a 5-watt device made of water and fat. The problem is clearly not hardware. Biology has discovered a mathematical formula for intelligence that we have not. By training smaller models, we move closer to uncovering that formula and to building pure reasoning systems.
AI Today
Large language models are trained as sophisticated parrots. They memorize vast knowledge and reproduce it fluently. Often, they connect disparate concepts, appearing to generalize and show sparks of general AI. But this generalization is largely accidental, a fortunate byproduct of training dynamics rather than an explicit objective.
In LLM training, when a sentence like “cats have four“ and “cats sleep a lot” receive similar gradient updates, their representations converge, creating a concept generalization, a mental representation of “cat”. Visualized in the latent space, they appear close to each other. Most of the time, however, similar concepts are scattered depending on initialization and training order, creating subnetworks that memorize two different, unconnected halves of the same concept.
Visualized in latent space, they are distant. Conceptual organization in LLMs is a random side effect, not a training objective.

Current research focuses on training larger LLMs because larger models create multiple redundant copies of knowledge, increasing the chance that similar concepts get connected in at least one subnetwork. However, this is highly inefficient.
Today, models have context windows up to 1 million tokens, which can fit complete files or even small coding projects. However, small context windows are the main bottleneck today, as the AI only has awareness of the data inside the context window. When working with tools like Claude Code, the AI reads code chunks and works with them, but because it is unaware of the rest of the code, it ends up generating many duplicate functions and calling the same variables in different ways. Because the context window is small, people rely heavily on internal model knowledge, which often turns out to be hallucinated. Internal knowledge is so unreliable that every AI tool today is instructed to search only and then quote the results instead of answering directly.
This, however, is possible only for question answering. For coding, people are trying to fit documentation into MCPs or LLM.md files so the AI can read it. But due to the small context window, in the current way of working, AI tries to write the code first and, when it fails, it checks the documentation to solve specific problems. Checking documentation first would not be possible because it can’t fit all in the context window. This also means that the code generated by LLMs is always for older library versions, and models need to be retrained frequently.
Analyzing the trends in AI
To understand where AI is going, two trends need to be taken into consideration:
Smaller models with better training techniques can compete with larger models
Due to market pressure, there are significant efforts to expand the context windows. A large context window could contain an entire codebase, along with libraries’ documentation, so the AI can be autonomous in writing code.
A promising line of research focuses on World Models, trained to understand concepts rather than to generate content. The combination of World Models and LLMs is showing some interesting progress. This will inevitably lead to better training techniques that make generalization a training objective rather than fortuitous events. Consequently, this will enable small models to generalize concepts more efficiently without duplicating knowledge across subnetworks, thereby further widening the gap to larger models.
Larger models can store more knowledge, but combining smaller models capable of good generalization with large context windows makes internal model memory less useful, or even undesirable.
The innovator’s dilemma
NVIDIA, OpenAI, and Google’s business models rely on paywalling APIs to large models that require complicated hardware setups. They cannot monetize small models, so they release them as open source.
Frontier models require large data centers with information moving on optical fibers and superconducting materials, powered by nuclear plants. In the meantime, human brains offer better performance on hardware made of water and fat, without even a decent conductor, and running on 5 watts of power. Still, the main focus is on larger data centers, more electricity, and even quantum computers, because that is the business model these companies follow with unprecedented CAPEX spending plans over the next decade.
But the problem evidently is not hardware. Biology simply knows a mathematical formula for intelligence that we have not yet discovered. Training smaller models will lead us closer to pure reasoning models, and it is possible that once knowledge is stripped away, what remains is some sort of pure mathematical structure of general reasoning itself. Training different models will lead to the same structure, even if masked by infinite invariant transformations. One day, we may find a canonical form that reveals this mathematical structure and allows us to write reasoning, general intelligence itself, in a symbolic language.
Today’s AI incumbents will have no moat selling APIs. They are mainframe companies; Small Language Models are PCs.
Small models that approach pure reasoning do not accumulate knowledge that becomes outdated, so they do not require retraining. Retraining is only needed to study stronger reasoning abilities. Being small and not requiring frequent updates, SLM can be printed directly onto hardware, offering small, low-power devices that can satisfy people’s needs. Large frontier models will not die. They will keep serving their market as IBM did in the mainframe era.
NVIDIA will keep making GPUs and will keep growing with virtual reality and other demands.
But under the radar, a new generation of startups building small models into devices will serve a market too small to sustain current incumbents. They will ignore it because of the innovator’s dilemma: the market is too small, and their customers demand larger frontier models and larger data centers. In the meantime, startups will provide small reasoning models to a new market with use cases that I can only speculate about and will probably get wrong; perhaps personal AI running on a phone. After all, in the 80s, small companies like Shugart started making small and cheap hard drives without a clear customer or market to serve, while the incumbents continued to focus on larger and more performant drives for mainframes.
And as with all innovator’s dilemma technologies, the first small models will have lower performance but also lower unit prices than paying for access to the frontier model.
However, over time, this market will grow exponentially, leading companies providing reasoning hardware to overtake incumbents.
LLM → SLM → RPU → Symbolic AI
LLM: Large Language Model with hundreds of billions of parameters
SLM: Small Language Model with less than a few billion parameters
RPU: Reasoning Processing Unit. SLM with almost no knowledge and a large context window
Symbolic AI: An intelligence algorithm rewritten from the black box of matrix multiplications into readable code
From SML to RPU
(From Small Language Models to Reasoning Processing Units)
Over the next 2 years, we expect the context window to grow to handle 5-10 million tokens, and models will get smaller and store less knowledge while specializing in context window understanding, intelligence, and reasoning.
We can call these SLM with minimal knowledge Reasoning Processing Unit (RPU).
An RPU is basically an AI CPU that receives instructions written in human language and executes them. As with today’s CPUs, the RPU will only process information, without any knowledge beyond essential firmware, such as linguistic skills to understand human languages.
The agent will load the context window with relevant knowledge from the RAG and can run a large number of reasoning steps across the entire knowledge base before generating any answer. Answers will be strongly based on the provided knowledge, with low risk of hallucinations. These models can run locally, protecting user privacy, and are significantly cheaper and faster than frontier models.
Once the rate of improvement begins to decrease and the small models stabilize, approximating pure reasoning and minimal knowledge, they will finally be printed into a hardware unit.
Thanks to low power consumption, privacy, low latency, no subscription required, and the ability to run without a connection, this new hardware could be used everywhere from the washing machine to a robot for space exploration.
RPUs may completely replace CPUs in many devices, and these devices will run programs written in plain English instead of rigid computer code.
From RPU to Symbolic AI
Small models of pure reasoning with no knowledge or little essential knowledge are much easier to study than large black boxes.
They can be iterated faster, training different architectures and with different techniques.
Because these models have limited knowledge, they pose lower security risks, such as bio-capabilities, no misalignment risks, fewer AI2027 scenarios, and are less susceptible to government control.
However, they also have more potential. Given their simplicity, it may be possible to understand the model’s math more quickly.
Understanding the math is not just for better training but also for understanding AI and rewriting their math into symbolic code. That will be a gradual process, where component after component will be rewritten, leading us to build rather than train AI.
Models get decompiled, leading to mechanistic interpretability. In other words, the understanding of how a neural network implements computations internally, at the level of circuits, algorithms, and representations.
Like a software engineer simplifying spaghetti code into a few elegant lines of code, it untangles the circuits into something logical, readable and explicit. The new AI is somewhere between a neural net and a traditional computer program, with much of its weights rewritten in readable code. It is smarter, faster, and more rational than trained AI.
At that point, RPU companies writing symbolic AI will own a technology that is one step beyond frontier models and AGI.
Note: The author does not own a crystal ball. This article is an educated guess formed by connecting observable trends. If you disagree, I’m happy to place a €100 bet.
Love this perspective so insightful. How incredible would it be to uncover biology's mathematical formula for intelligence?